


Von über 200 SEO-Rankingfaktoren ist Duplicate Content (Doppelter Inhalt) wohl der Bekannteste. Duplicate Content ist einer der häufigsten Faktoren, durch den Webseiten schlecht in der Suchmaschine auffindbar sind. Was es mit Duplicate Content auf sich hat, wie man ihn vermeidet und welche Duplicate Content Checker es gibt, um den doppelten Inhalt überhaupt zu finden, zeigen wir heute. Da der Beitrag wieder einmal sehr umfangreich wird, kann man unter folgenden Links zum gewünschten Kapitel springen.
- Was ist Duplicate Content?
- Welche Arten Duplicate Content gibt es?
- Wird doppelter Content bestraft?
- Wie finde ich Duplicate Content?
- Wie vermeide ich Duplicate Content?
Was ist Duplicate Content?
Duplicate Content bedeutet auf Deutsch: Doppelter Inhalt – auch gerne in Kurzform DC benannt. Es gibt mehrere Formen, wie ein doppelter Inhalt zustande kommen kann. Bei einem doppelten Inhalt ist der gleiche Text über mehrere URLs erreichbar. Gerade, wenn man nicht der geistige Eigentümer und Erst-Publisher ist, kann man dadurch seiner Webseite in den Suchergebnissen schaden. Auch ähnliche Inhalte werden gerne als doppelter Inhalt bezeichnet, obwohl der englische Begriff Common Content deutlich besser ist und hilft, die zwei Varianten auseinander zu halten.
Welche Arten Duplicate Content gibt es?
Je nachdem, ob die doppelten Inhalte auf der eigenen oder auf einer fremden Webseite nochmals auftauchen, spricht man von internem Duplicate Content oder externem Duplicate Content.
Copy and Paste Texte klauen
Die doppelten Inhalte können auf der eigenen Seite oder auch auf fremden Webseiten liegen. Der häufigste Grund für Duplicate Content ist, dass Webseitenbetreiber sich nicht die Mühe machen, eigene einzigartige Inhalte zu erschaffen, sondern per Copy and Paste die Inhalte auf anderen Webseiten oder beispielsweise beim Hersteller „klauen“ und dann einbinden. Es gibt zwar keine expliziten Strafen seitens Google für doppelte Inhalte, aber man schadet dem Ranking trotzdem nachhaltig, da durch den doppelten Inhalt die eigene Seite keinen besonderen Wert erreicht.

© contrastwerkstatt – Fotolia.com
Gleiche Artikel – gleiche Beschreibung
Ein anderes Problem mit Duplicate Content entsteht beispielsweise bei Onlineshops, wenn es ein Produkt gibt, dass eigentlich identisch, aber in mehreren Variationen verfügbar ist. Als Beispiel kann man hier ein T-Shirt in unterschiedlichen Farben oder ein Getränk mit unterschiedlicher Füllmenge genannt werden. Diese Produkte bekommen vom Shop-Betreiber oft keine eigene Produktbeschreibung und sind vom Inhalt identisch. Das Problem wird noch dadurch verstärkt, wenn man Google nicht hilft zu erkennen, dass es sich um die gleichen Artikel handelt. Eine gängige Lösung ist es, alle gleichen Artikel unter einem Vaterartikel als Kindartikel zusammenzufassen. Wenn man sehr viele Artikel hat, macht es zusätzlich Sinn, mit dem Canonical-Tag zu arbeiten und so die Zahl der indexierten Seiten zu reduzieren, bzw. den Vaterartikeln mehr Gewichtung zu geben.
Schlechte URL-Struktur
Häufig sieht man bei technisch nicht sonderlich durchdachten Webseiten, dass eine Seite unter mehreren URLs erreichbar ist. Dadurch entsteht natürlich auch Duplicate Content.
Beispiele:
Wenn eine Webseite über Kurz-Schreibweisen mehrfach erreichbar ist.
https://www.irgendeinedomain.com/hauptkategorie/produkt
https://www.irgendeinedomain.com/produkt
oder
Wenn eine Webseite versucht die Ansicht übersichtlicher zu machen und dazu mehrere Seiten verwendet, welche eine neue URL erzeugen, wobei der Kategorietext der gleiche ist oder die Produkte per Shuffle identisch sein können.
https://www.irgendeinedomain.com/produkt
https://www.irgendeinedomain.com/produkt_1
https://www.irgendeinedomain.com/produkt_2
oder
Wenn eine Webseite über die verschlüsselte und unverschlüsselte Adresse zu erreichen ist. Hier ist eine Weiterleitung sinnvoll.
https://www.irgendeinedomain.com
http://www.irgendeinedomain.com
oder
Wenn eine URL sowohl über die Groß- als auch Kleinschreibung erreichbar ist. Eine Weiterleitung auf eine einheitliche Schreibweise ist angebracht.
https://www.irgendeinedomain.com/produkt
https://www.irgendeinedomain.com/Produkt
oder
Wenn eine Webseite mit www. und ohne erreichbar ist. Besser ist hier eine Weiterleitung.
https://irgendeinedomain.com
https://www.irgendeinedomain.com
oder
Wenn eine URL Session-IDs verwendet, welche im schlechtesten Fall auch noch verlinkt werden.
https://www.irgendeinedomain.com/produkt/sess-id/bdjh98sd7782bs-332332bmnjbn2-233dbbd
Unterschiedliche Sprachen
Ein weiteres Problem ist, wenn eine Webseite mit mehreren Sprachen auf dem selben Suchmarkt aktiv ist. Beispielsweise werden englische und deutsche Inhalte von google.de präsentiert. Mit dem hreflang-Guide kann man dieses Problem umgehen.
Mehrere Domains
Viele Seitenbetreiber nutzen mehrere Domains. Teilweise, um mehrsprachig aufzutreten, teilweise erhoffen sie sich dadurch, ein höheres Ranking bzw. mehr Sichtbarkeit im Internet zu erlangen. Mehrere Domains zu haben ist in Ordnung, wichtig ist, dass diese mit einer 301-Weiterleitung auf die richtige Seite zeigen. Ansonsten entsteht wieder Duplicate Content.
Automatisierte Textverbreitung
Es gibt tatsächlich immer noch SEOs, die Schnittstellen auf Webseiten einbauen, welche automatisiert News von anderen Seiten 1:1 wiedergeben und hoffen so mehr Inhalte zu schaffen und bei Google gefunden zu werden. Auch dieses Vorgehen ist mehr als kontraproduktiv.
Mobile Webseiten
Mobile Webseiten, welche eine andere URL haben, aber den gleichen Inhalt bieten, zählen auch zu einer Variante von doppeltem Inhalt. Hier sollte man Google zeigen, dass es sich um eine Mobilseite handelt. Der beste Weg ist ohnehin eine Webseite die responsive ist und nicht unterschiedliche URLs verwendet.
PDF- und Druckdateien
Wer eine auf einer Seite den gleichen Inhalt nochmal als PDF anbietet, der läuft auch Gefahr, dass dies als Duplicate Content angesehen wird.
Doppelter Content der erlaubt ist
Inhalte in unterschiedlichen Sprachen oder Zitate sind kein Duplicate Content. Wer Zitate verwendet, sollte aber auch dafür sorgen, dass die Suchmaschine sie als solche erkennt. Das kann man im HTML-Quelltext über folgende Auszeichnung erreichen:
<blockquote>Zitat<cite>Autor oder Quelle</cite></blockquote>
Wird doppelter Content bestraft?
Duplicate Content ist kein – wie häufig falsch angenommen – Spam. Es gibt diverse Strafen englisch: Penalty, welche Webseiten für bestimmte Handlungen abstrafen, dazu zählt DC nicht. Wer allerdings absichtlich Content auf fremden Webseiten klaut, um das eigene Ranking zu verbessern, der muss mit einer Abwertung der eignen Webseite rechnen. In der Regel erfolgt auch hier keine Strafe, sondern eine Verminderung der Sichtbarkeit.
Ein oft zu beobachtendes Phänomen ist, dass Seiten mit gleichen Inhalten sich das Ranking teilen. Im Vordergrund steht, dass man den Suchmaschinen-Nutzern ein einmaliges Erlebnis bietet, wer keine Inhalte liefert, der bietet auch keinen Anhaltspunkt, dass die Seite einen Besuch wert ist, wer keine anderen Inhalte als andere Webseiten anbietet, der hat keine Argumente, dass die eigene Webseite, statt anderer Seiten angezeigt werden sollten.
Wer sich mit den Richtlinien von Google für Webmaster auseinandersetzt, wird feststellen, dass Google bei unbeabsichtigtem Duplicate Content eigenständig entscheidet, welches Ergebnis das Beste ist.
Warum schadet Duplicate Content der Webseite?
Auch wenn es dem ungeübtem Webseitenbesitzer ersteinmal ärgerlich erscheint und man nicht genau erkennen kann, was es bringt, Texte, die es schon gibt noch einmal zu überarbeiten, genauer zu recherchieren und so mit viel Arbeit verbunden Inhalte zu erschaffen, welche man doch ganz einfach per Copy and Paste mit den Menschen teilen könnte. Doch wenn man genauer darüber nachdenkt, ist der Grund logisch und einleuchtend.
Google möchte Unternehmer nicht ärgern und unnötig Arbeit machen, sondern seinen Nutzern immer das beste Erlebnis bieten. Dazu zählt, dass jedes Suchergebnis nicht nur die Suchintention erfüllt, sondern auch ein einmaliges Erlebnis darstellt. Wenn jetzt jede Webseite den gleichen Inhalt hätte, dann gäbe es gar keinen Grund, mehr als ein Ergebnis anzuzeigen, da es für den Suchenden nichts als Arbeitsaufwand wäre, sich noch weitere Suchergebnisse anzusehen. Somit kommt es auch in der Regel dazu, dass Google Seiten die Duplicate Content bereitstellen, entweder nicht großartig wertet oder gar nicht erst indexiert, da sie keine wirkliche Relevanz haben.
Ein weiterer Fall, dass eine Webseite sich durch Duplicate Content selber schadet ist, dass Google nicht genau weiß, ob es bestimmte Seiten überhaupt indexieren sollte oder ob ein Inhalt wie beispielsweise bei einer mehrsprachigen Seite, die nicht richtig ausgezeichnet ist, überhaupt ein relevantes Suchergebnis darstellt.
In den meisten Fällen von DC erkennt Google ziemlich genau, was der unrelevantere doppelte Content ist und nimmt das Problem selbst in die Hand. Leider ist das Ergebnis nicht immer zwangsläufig das Beste für den Webseitenbetreiber. Man sollte aber auch wissen, dass Google zwischen zwei Arten von doppeltem Inhalt unterscheidet, einmal dem versehentlich doppeltem Inhalt und dem böswilligem. Natürlich ist zweiteres deutlich schädlicher.
Wie finde ich Duplicate Content?
Duplicate Content Checker
Duplicate Content Checker gibt es viele, doch nicht alle haben die gleichen Funktionen und nicht jeder ist wirklich zuverlässig. Welche Duplicate Content Checker es gibt und wie man mit ihnen umgeht, zeigen wir im Folgenden.
Sistrix Optimizer
Als erstes können wir mal wieder unser Lieblingswerkzeug, wenn es um SEO Tools geht, nennen: Sistrix. Wer den Optimizer gebucht hat oder die Vollversion gerade testet, kann diesen dazu nutzen, um technisch zu prüfen, ob mehrere URLs den gleichen Inhalt zeigen. Wenn der Optimizer durchgelaufen ist, kann man die Daten ganz einfach als Excel-Tabelle exportieren und in Ruhe prüfen.
Siteliner für internen DC
Je nachdem wie umfangreich die Seite ist, kann man sie mit Siteliner kostenlos crawlen lassen. Man erhält einen übersichtlichen Report mit Grafiken. Siteliner bietet noch viele weitere nützliche Informationen, wie beispielsweise defekte Links. Das funktioniert auch sehr zuverlässig, leider nur bis zu einer bestimmten Anzahl an URLs. Danach braucht man Siteliner Premium, um alle Ergebnisse angezeigt zu bekommen.
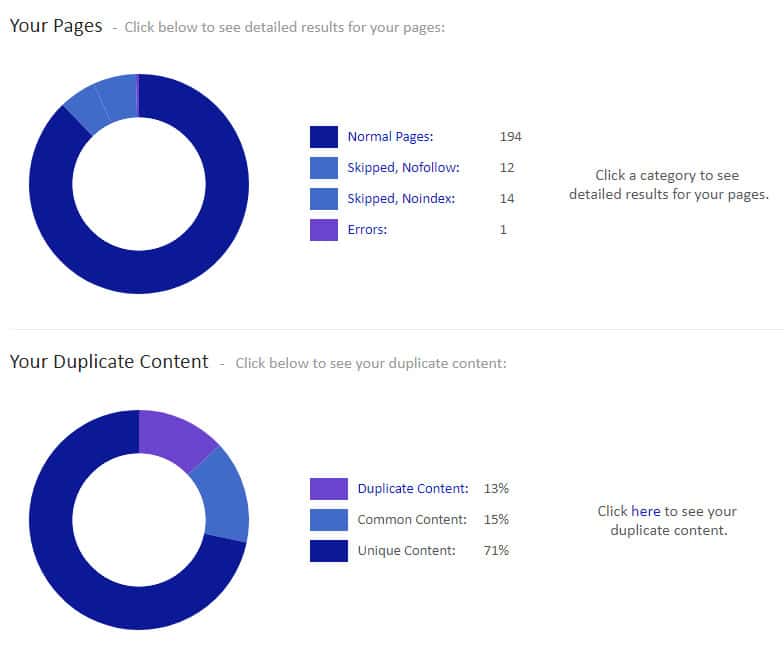
In der weiteren Übersicht kann man genau einsehen, wo man den Duplicate Content findet. Wobei man bei einer gewissen Zahl von doppeltem Content nicht in Panik geraten darf, oft entsteht die Dopplung durch Banalitäten wie den gleichen Footer, was an sich nicht weiter schlimm ist.
Google für externen DC
Während es für internen doppelten Content eine Vielzahl an Tools gibt, sieht es bei externem Duplicate Content deutlich schlechter aus. Am zuverlässigsten verläuft hier die manuelle Prüfung bei Google. Man nimmt eine längere Textpassage und gibt diese in die Googlesuche ein. Wenn der eingegebene Text gefunden wird, taucht im Idealfall nur die eigene Seite mit fett markierten Buchstaben auf. Sollten andere Seiten den gleichen Inhalt haben, dann gilt es zu handeln.
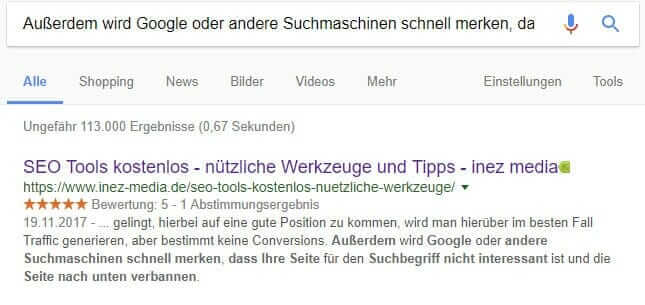
Wie man sieht, haben wir unseren Blogbeitrag über nützliche Tools nicht abgeschrieben.
Copyscape für externen DC
Copyscape soll im Grunde so funktionieren wie Siteliner, nur dass man hier externen DC prüft. Man gibt eine URL ein und der Duplicate Content Checker prüft, ob es den Inhalt bereits auf einer anderen Webseite gibt. Leider funktioniert es nicht zuverlässig. Wir haben das Tool an mehreren Seiten, welche wir einwandfrei als DC identifizieren konnten getestet und sehr oft lieferte Copyscape keine Ergebnisse. Als Erklärung wurde angegeben, dass es sich hierbei, sofern keine Ergebnisse angezeigt werden, um Webseiten handelt, welche nicht indexiert sind. Das stimmt so leider nicht, daher ist die sicherste Methode einfach Google zu nutzen.
Wie vermeide ich Duplicate Content?
Je nach Problem gibt es immer eine passende Lösung. Daher sollte man nicht verzweifeln.
Up to date bleiben
Damit man technisch auf dem Laufenden bleibt und keine Fehler begeht, macht es Sinn sich hin und wieder mit den Regeln der Suchmaschinen auseinanderzusetzen. Vor allem Google ist hier die wohl die wichtigste Anlaufstelle.
Keine Texte und Inhalte klauen
Die wichtigste Regel ist wohl, sich nicht den Content anderer Seiten anzueignen. Es ist teilweise besser, gar keinen Inhalt zu zeigen, als die Webseite mit geklauten Inhalten zu füllen. Natürlich ist die Speisung mit unique Content mühsam und zeitaufwändig, aber gleichzeitig auch die beste Chance, in der Suchmaschine aufzusteigen.
Korrekte Einstellung in der Search Console
Die Search Console (alt: Webmaster Tools) stellt Webmastern diverse Werkzeuge bereit. Unter anderem kann man bestimmen, wie Webseiten indexiert werden sollen, Auch kann man eine Indexierung per Hand anstoßen.
Sprache wählen (hreflang)
Damit die Suchmaschine nicht in die Verlegenheit kommt, unterschiedliche Sprachen einer Webseite im falschen Land zu indexieren, wie beispielsweise italienische Ergebnisse unter google.de statt google.it, sollte man die hreflang-Anmerkung nutzen. Auch bei Webseiten, die für unterschiedliche Sprachen und Länder unterschiedliche Domains nutzen (Beispiel: .de und .com), ist es sinnvoll, diese zusammenzuführen und die Anmerkung zu verwenden. So stärkt man die Sichtbarkeit und muss nicht mehrere Webprojekte betreiben.
Domainregel für www.
Damit eine Webseite nicht unter www. und ohne www.-Schreibweise erreichbar ist, sondern eine Variante auf die andere weiterleitet, wird in der .htaccess-Datei eine ModRewrite-Umleitung eingerichtet. Hier ist es sinnvoll, sich für genau eine Regel zu entscheiden. Unser Favorit ist die Schreibweise mit www..
301-er Weiterleitung
Diese Form der Weiterleitung kommt zum Einsatz, wenn es eine alte Webseite nicht mehr gibt und so eine 404-Fehlerseite entstehen würde. Damit die URL-Eingabe oder der Link dennoch zum richtigen Ziel führt, kann man eine 301-er Weiterleitung einrichten. Man braucht den Verlust der Sichtbarkeit nicht , wie früher von einigen Admins angenommen, fürchten.
Noindex, um eine Indexierung zu vermeiden
Wenn man in den META-Tags eine Seite mit noindex auszeichnet, gibt man Suchmaschinen die Anweisung, die Seite in den Suchergebnissen zu ignorieren. Die meisten Suchmaschinen wie beispielsweise Google befolgen diesen Befehl. Dies ist eine Lösung, damit unwichtige Seiten, die doppelte Inhalte haben, nicht einer anderen Seite das Ranking streitig machen. Wichtig ist, dass man die Seite trotzdem auf „follow“ lässt, damit die Suchmaschinen sie einsehen und crawlen können. Noindex ist aber auch ein gutes Mittel, wenn man sehr viele Seiten hat (beispielsweise durch mehrere tausend Produkte) und durch Verhinderung einer Indexierung die Wichtigkeit der anderen Seiten stärken will, sprich es geht hier nicht immer um Duplicate Content.
Canonical Tag (rel=canonical)
Die Arbeit mit dem Canonical muss man sich so vorstellen, als ob man diverse Seiten hat, die fast identisch sind, welche auf einer Seite zusammengefasst werden. Nehmen wir an, Sie verkaufen T-Shirts und diese unterscheiden sich nur in der Farbe, sie haben aber vom gleichen T-Shirt so viele Farbkombinationen, dass dadurch viel zu viele Seiten entstehen, welche keinen Mehrwert bieten würden. Hier würde eine Zusammenfassung unter einem Vaterartikel Sinn machen und von den Kindartikeln per Canonical-Tag auf den Vater zu verweisen. So würde Google nur diesen indexieren, ihn als deutlich stärker gewichten und die Kunden würden trotzdem alle anderen Artikel von diesem Vaterartikel aus erreichen. Google sagt folgendes hierzu: „Eine kanonische Seite ist die bevorzugte Version mehrerer Seiten mit ähnlichen Inhalten.″
Das Canonical-Tag kann aber auch zum Einsatz kommen, wenn der Inhalt komplett identisch ist, wie bei der Druckversion einer Webseite. So kann man Google zeigen, wo das Original zu finden ist und welche Seite wichtiger ist.
Fazit zu doppelten Inhalten
Selbst affine Webmaster ignorieren teilweise Duplicate Content, dabei ist der doppelte Inhalt meist die größte Ressource zur Verbesserung der Sichtbarkeit. Einzigartige Inhalte sind unbezahlbar und bringen einen bei der Suchmaschinenoptimierung weiter voran. Wer diese Thematik ernst nimmt, hat gute Chancen die Webseite nachhaltig aufzuwerten.



Kommentare