


Of over 200 SEO ranking factors, Duplicate Content is probably the best known. Duplicate content is one of the most common factors that make websites difficult to find in search engines. What Duplicate Content is all about, how to avoid it and which Duplicate Content Checkers are available to find Duplicate Content at all, we will show today. As the article will once again be very extensive, you can jump to the desired chapter by following the links below.
-
- What is Duplicate Content?
- What types of duplicate content are there?
- Is duplicate content penalized?
- How do I find duplicate content?
- How do I avoid duplicate content?
Duplicate Content means in German: Doppelter Inhalt – also known as DC. There are several ways how a duplicate content can be created. In the case of a duplicate content, the same text is accessible via several URLs. Especially if you are not the intellectual owner and first publisher, this can damage your website in the search results. Similar content is also often referred to as duplicate content, although the English term Common Content is much better and helps to keep the two variants apart.
What types of duplicate content are there?
Depending on whether the duplicate content reappears on your own website or on a third-party website, this is called internal duplicate content or external duplicate content.
e.g;
Copy and Paste steal texts
The duplicate contents can be on the own site or on external websites. The most common reason for duplicate content is that website operators don’t bother to create their own unique content, but rather copy and paste the content onto other websites or, for example, “steal” it from the manufacturer and then integrate it. Although there are no explicit sanctions from Google for duplicate content, you still damage the ranking in the long run, because the duplicate content does not give your own site any special value.

© contrastworkshop – Fotolia.com
Same articles – same description
Another problem with duplicate content arises, for example, in online shops when there is a product that is actually identical but available in several variations. As an example, a T-shirt in different colours or a drink with different contents can be mentioned here. These products often do not get their own product description from the shop owner and are identical in content. The problem is intensified if you don’t help Google to recognize that these are the same items. A common solution is to group all the same items under a parent item as a child item. If you have a lot of articles, it also makes sense to work with the Canonical tag to reduce the number of indexed pages or to give more weight to the parent articles.
Bad URL structure
Often you can see with technically not very well thought out websites that a page is accessible under several URLs. This of course results in duplicate content.
examples:
If a web page can be reached several times using short spellings.
https://www.irgendeinedomain.com/hauptkategorie/produkt
https://www.irgendeinedomain.com/produkt
or
If a website tries to make the view clearer by using multiple pages that generate a new URL, where the category text is the same or the products can be identical by shuffle.
https://www.irgendeinedomain.com/produkt
https://www.irgendeinedomain.com/produkt_1
https://www.irgendeinedomain.com/produkt_2
or
If a website can be reached via the encrypted and unencrypted address. Forwarding is useful here.
https://www.irgendeinedomain.com
http://www.irgendeinedomain.com
or
If a URL is case-sensitive. A redirection to a uniform spelling is appropriate.
https://www.irgendeinedomain.com/produkt
https://www.irgendeinedomain.com/Produkt
or
If a website is accessible with www. and without. Better here is a forwarding.
https://irgendeinedomain.com
https://www.irgendeinedomain.com
or
If a URL uses session IDs, which are linked in the worst case.
https://www.irgendeinedomain.com/produkt/sess-id/bdjh98sd7782bs-332332bmnjbn2-233dbbd
Different languages
Another problem is when a website with several languages is active in the same search market. For example, English and German contents are presented by google.de. With the hreflang-Guide you can avoid this problem.
Several domains
Many site operators use several domains. Partly in order to appear multilingual, partly they hope to achieve a higher ranking or more visibility on the Internet. Having multiple domains is fine, but it is important that they point to the right page with a 301 redirect. Otherwise duplicate content will be created again.
Automated text distribution
In fact, there are still SEOs who build interfaces into websites that automatically display news from other sites 1:1 and hope to create more content and be found on Google. This approach is also more than counterproductive.
Mobile websites
Mobile websites that have a different URL but offer the same content also count as a variant of duplicate content. Here you should show Google that this is a mobile page. The best way is anyway a web page that is responsive and does not use different URLs.
PDF and print files
Whoever offers the same content on a page as PDF again, runs the risk that this will be considered duplicate content.
Duplicate content that is allowed
Content in different languages or quotations is not duplicate content. However, anyone who uses quotations should also ensure that the search engine recognizes them as such. This can be achieved in HTML source code by using the following markup:
<blockquote>quote<cite>author or source</cite></blockquote>
Will duplicate content be penalized?
Duplicate content is not – as often wrongly assumed – spam. There are several penalties: Penalty, which punish websites for certain actions, DC is not one of them. However, if you deliberately steal content from other websites in order to improve your own ranking, you must expect a devaluation of your own website. As a rule, this is not a punishment, but a reduction in visibility.
An often observed phenomenon is that pages with the same content share the ranking. The main point is to offer search engine users a unique experience, if you don’t provide content, you don’t offer any indication that the site is worth a visit, if you don’t provide content other than other websites, you have no arguments that your own website should be displayed instead of other sites.
If you read the guidelines of Google for webmasters, you will find that Google decides independently which result is best in case of unintentional duplicate content.
Why does duplicate content harm the web page?
Even if it seems annoying to the inexperienced website owner at first and you can’t see exactly what’s the point of revising texts that already exist, researching them more precisely and thus creating content that involves a lot of work, which you could easily share with people by copy and paste. But if you think about it more carefully, the reason is logical and obvious.
Google does not want to annoy entrepreneurs and make unnecessary work, but always wants to offer its users the best experience. This means that every search result not only fulfils the search intention, but also represents a unique experience. If every web page had the same content, there would be no reason to display more than one result, as it would be nothing but work for the searcher to look at more search results. As a result, Google pages that provide duplicate content either don’t score highly or aren’t indexed at all because they have no real relevance.
Another case where a web page is harming itself through duplicate content is that Google does not know whether it should index certain pages at all or whether a content, such as a multilingual page that is not properly tagged, is a relevant search result at all.
In most cases of DC, Google pretty much recognizes what the less relevant duplicate content is and takes the problem into its own hands. Unfortunately the result is not always necessarily the best for the website operator. But you should also know that Google distinguishes between two types of duplicate content, the accidental duplicate content and the malicious duplicate content. Of course, the second is much more harmful.
Duplicate Content Checker
There are many Duplicate Content Checker, but not all of them have the same features and not everyone is really reliable. Which Duplicate Content Checkers are available and how to handle them is shown below.
Sistrix Optimizer
First of all, we can once again name our favorite tool when it comes to SEO Tools: Sistrix. If you have booked the optimizer or are currently testing the full version, you can use it to check technically whether several URLs show the same content. Once the optimizer has run through, you can easily export the data as an Excel spreadsheet and check it at your leisure.
Siteliner for internal DC
Depending on how extensive the site is, you can crawl it with Siteliner for free. You get a clear report with graphics. Siteliner offers a lot more useful information, such as broken links. This also works very reliably, unfortunately only up to a certain number of URLs. After that you need Siteliner Premium to get all results.
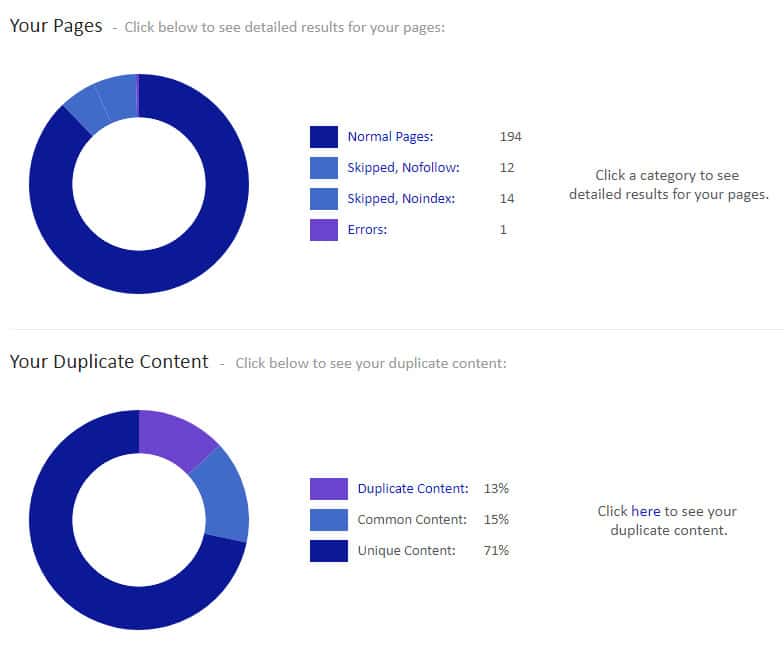
In the further overview you can see exactly where to find the Duplicate Content. Whereby one should not panic when there is a certain amount of duplicate content, often the duplication is caused by banalities like the same footer, which in itself is not too bad.
Google for external DC
While there are a variety of tools available for internal duplicate content, external duplicate content looks much worse. The most reliable way to check for duplicate content is to manually check it with Google. One takes a longer text passage and enters it into the Google search. If the entered text is found, ideally only the own page with bold letters will appear. If other pages have the same content, then action must be taken.
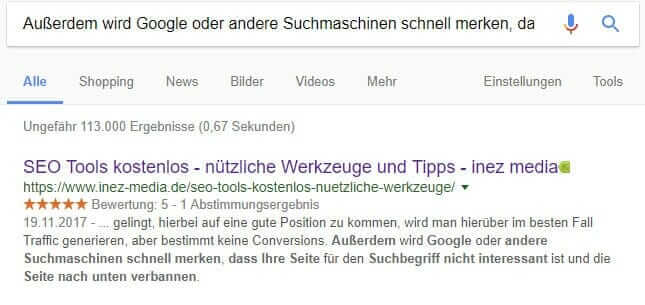
As you can see, we have not written off our blog post about useful tools.
Copyscape for external DC
Copyscape should basically work like Siteliner, except that you check external DC here. You enter a URL and the Duplicate Content Checker checks if the content already exists on another website. Unfortunately it does not work reliably. We have tested the tool on several sites which we could identify as DC and very often Copyscape did not give any results. As an explanation it was stated that, if no results are displayed, these are websites which are not indexed. Unfortunately this is not true, so the safest method is to use Google.
Depending on the problem, there is always a suitable solution. Therefore one should not despair.
Stay up to date
In order to stay technically up to date and not make any mistakes, it makes sense to deal with the rules of the search engines from time to time. Especially Google is probably the most important contact point here.
Don’t steal any texts or contents
The most important rule is probably not to appropriate the content of other sites. It is sometimes better to show no content at all than to fill the website with stolen content. Of course, feeding the site with unique content is tedious and time-consuming, but at the same time it is the best chance to get ahead in the search engine.
Correct setting in the Search Console
The Search Console (old: Webmaster Tools) provides webmasters with various tools. Among other things, you can determine how web pages should be indexed, and you can also trigger indexing by hand.
Choose language (hreflang)
To avoid the search engine being embarrassed by indexing different languages of a website in the wrong country, such as Italian results at google.de instead of google.it, you should use the hreflang annotation. Even for websites that use different domains for different languages and countries (example: .de and .com), it makes sense to merge them and use the hreflang annotation. This way you can increase visibility and do not have to run several web projects.
domain rule for www.
To ensure that a website is not reachable under www. and without www. spelling, but instead redirects one variant to the other, a ModRewrite redirection is set up in the .htaccess file. Here it makes sense to choose exactly one rule. Our favorite is the spelling with www.
301-er redirection
This form of redirection is used when an old website no longer exists and a 404 error page would result. To make sure that the URL input or the link still leads to the correct destination, you can set up a 301 redirection. You do not need to fear the loss of visibility, as some admins used to assume.
Noindex to avoid indexing
If you mark a page with noindex in the META tags, you give search engines the instruction to ignore the page in the search results. Most search engines such as Google follow this command. This is a solution so that unimportant pages that have duplicate content do not take the ranking from another page. The important thing is to keep the page on “follow” anyway, so that the search engines can view and crawl it. Noindex is also a good tool if you have a lot of pages (e.g. several thousand products) and want to strengthen the importance of the other pages by preventing indexing, i.e. this is not always about duplicate content.
Canonical Tag (rel=canonical)
One has to imagine the work with the Canonical as if one has several pages that are almost identical, which are summarized on one page. Suppose you sell T-shirts and they only differ in colour, but they have so many colour combinations from the same T-shirt that this results in far too many pages that would offer no added value. Here a summary under a father article would make sense and to refer from the child articles by Canonical tag to the father. This way Google would only index this father, weight him as much stronger and the customers would still reach all other articles from this father article. Google says the following: “A canonical page is the preferred version of several pages with similar content.″
The Canonical tag can also be used if the content is completely identical to the print version of a website. So you can show Google where to find the original and which page is more important.
Conclusion on duplicate content
Even affine webmasters sometimes ignore duplicate content, and duplicate content is usually the greatest resource for improving visibility. Unique content is priceless and helps you advance in search engine optimization. If you take this topic seriously, you have a good chance to increase the value of your website.


Comments